Organizations are creating and consuming data at an unprecedented rate, and better management solutions are essential if that data is to be managed effectively. This is a particular challenge when capturing different commodities within individual Energy Trading and Risk Management (ETRM) systems. In this article, we highlight the key decisions for energy companies when introducing a reporting system across multiple ETRMs.
For any end-to-end ETRM transaction, organizations require a significant amount of complex data to support the process from start to finish. This includes transaction data, market data, valuation results, reference data, scheduling data, invoice data, and actualization data. This data often resides in multiple locations such as ETRMs, ERP systems, and even spreadsheets. It is no wonder that companies find it both difficult and costly to manage and consolidate information scattered across many disparate systems.
Risk management is a good example. Management teams need a holistic view of exposure across systems and commodities. However much of this data is not in a standardized format and hence ill-suited for most reporting systems. Variations in data naming and organization add to the complexity, making it challenging to consolidate everything into a single source.
MASTER DATA MANAGEMENT
Data redundancy and inconsistencies are common issues in the energy business. To solve this problem and provide a solid foundation for reporting, organizations must establish and maintain a master source of reference data.
Master Data Management (MDM) is a process that enables businesses and IT to support all their essential data from one single source (master data source) that acts as a common reference platform (see Figure 1). MDM provides accurate, trustworthy data that can be shared across multiple downstream and upstream systems. Given that data is sourced from a single location without affecting transactional systems, MDMs significantly streamline the process of populating reporting reference data (dimensions).
In a perfect world, MDM systems are populated with data via a user interface (UI), which is then published to other referencing systems. However, in most environments, master data is populated through a mix of UI entry and subscription from other sources. For instance, a new customer record is created in the MDM system and pushed out to where it is needed. Conversely, a new general ledger code might be created in the ERP system, and published to the MDM.
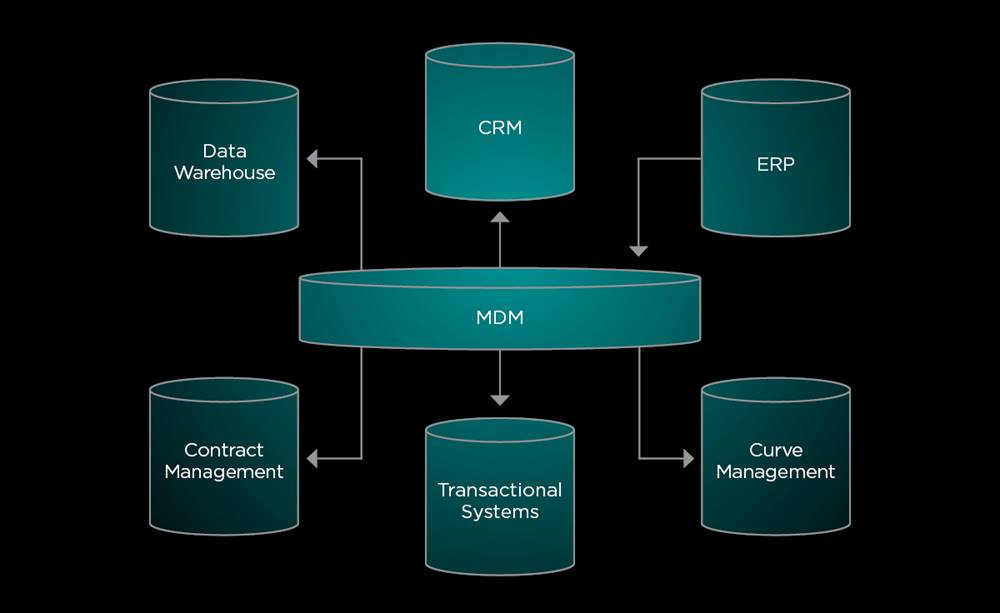
Figure1: Example MDM model
REPORTING DATA MODELS
A ‘star schema’ database model is popular and effective for reporting applications. This design optimizes query performance for analytical queries rather than transactional queries. This makes it easier to navigate and understand for business users with less technical knowledge.
This approach uses dimension modeling, which comprises two types of table (see Figure 2). The fact table contains the quantitative data or measures of the business such as trades and exposures, while the dimension tables provide descriptive attributes by which measures are analyzed. For example, an ETRM reporting data model would have a trade fact table with dimensions such as time, product, customer, and location.
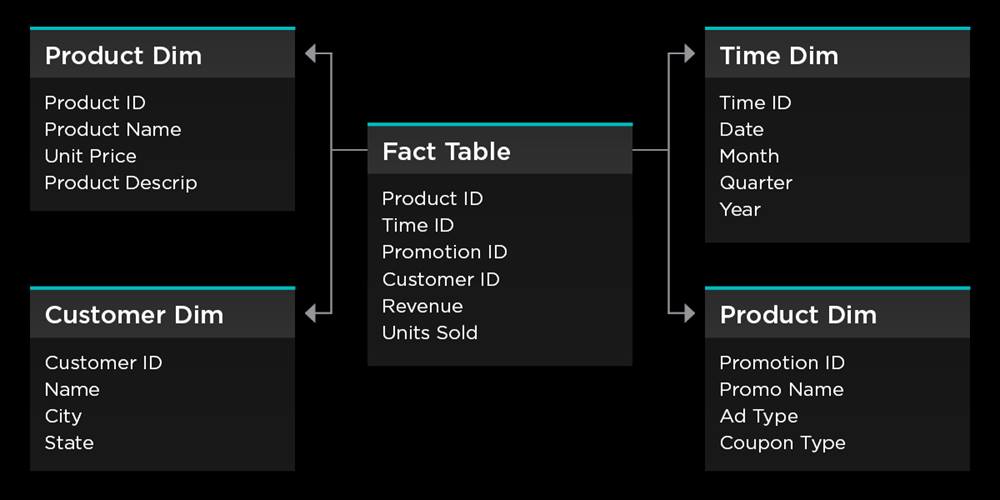
Figure 2: Example star schema
REPORTING ACROSS MULTIPLE ETRMS
When reporting across multiple ETRMs, organizations should consider five key dimensions.
1. Capture all transactions into staging tables of raw data
An operational data store (ODS) is a centralized database that combines data from multiple systems into a single location. It provides a real-time snapshot of an organization's current data, which enables decision-makers make informed decisions while business operations are taking place.
The first step in populating an ODS is to extract the data from its source. Too often, query and translation logic are embedded into the extraction code, which may limit and alter the raw data. A better approach is to separate the extraction function from the translation logic to isolate data-loading tasks.
For each ETRM or source system, a scheduled process should extract trade and valuation data into the staging tables of a separate, dedicated database. This offers many advantages. By centralizing all trade data in staging tables, you can ensure that any number of downstream applications receive accurate and complete information without inconsistencies and modification.
Furthermore, you can use a single set of queries to extract data from the ETRMs, on a set schedule. This prevents multiple systems from using different methods to access a transactional system at different times throughout the day. This greatly simplifies support and system performance. Finally, connectivity and network issues are isolated from translation logic, so nothing is ‘lost in translation’.
In other words, success depends on obtaining raw data efficiently via a consistent import function. Companies should also take advantage of robust error reporting to log and publish any failures to support personnel.
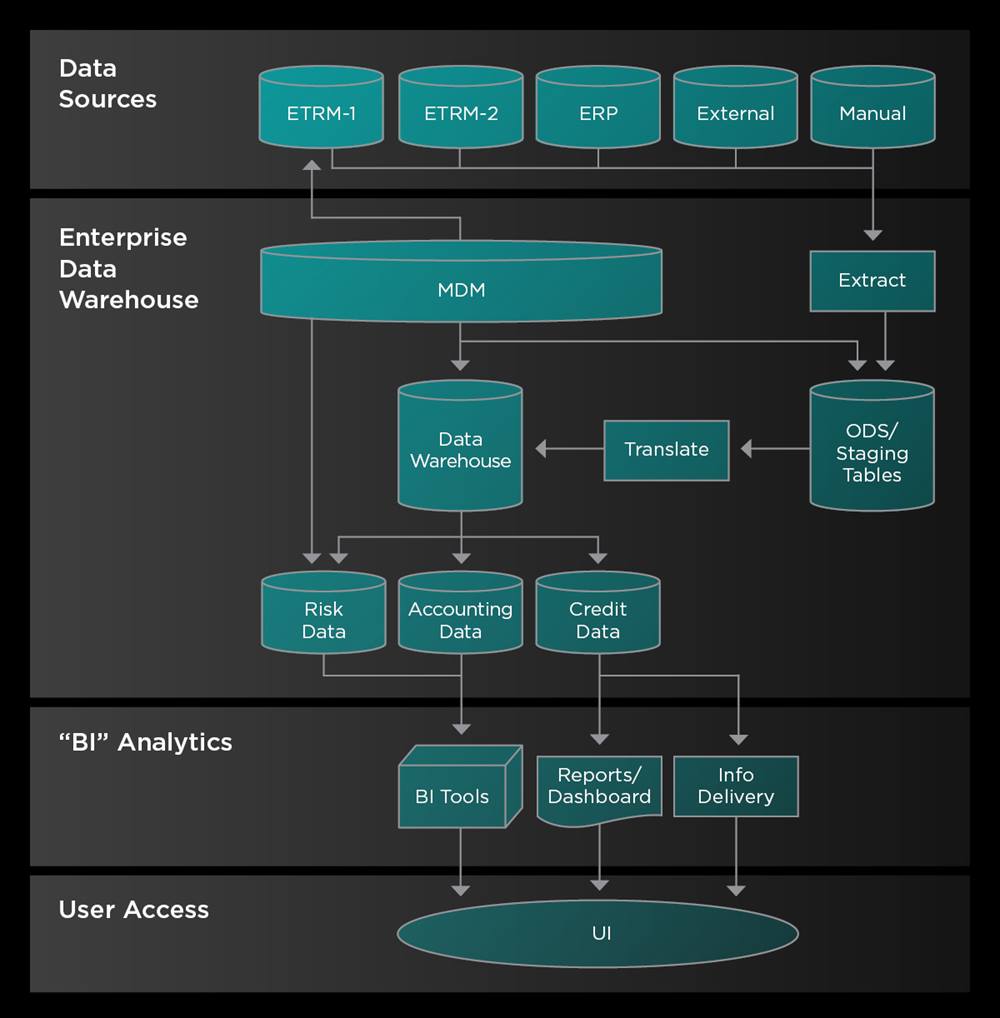
Figure 3: Example enterprise data flow
2. Perform translation to populate a data warehouse
Having populated the staging tables, it is time to translate and transform trade data into a general data warehouse or purpose-specific data mart schemas. In the case of a Risk and P&L reporting data mart, an automated process will need to populate a set of trade and exposure fact tables for all commodities.
Values and volumes should be captured in the greatest detail required to meet reporting requirements – hourly, daily or monthly, for example. Fact tables are supported by a shared set of commodity agnostic dimension tables. Companies should undertake careful thought and analysis to ensure that current and future risk reporting needs are satisfied.
Additional data marts may be created to support:
- Settlements
- Credit
- ERP integration
- Data warehousing
- General reporting.
3. Reference data
MDM dimension tables must be updated on a schedule consistent with the fact tables and based on similar parameters. Translation logic will fail if a dimension value cannot be referenced when processing transactions. While reference data doesn’t change often, if processes encounter a new reference they must be able to look up the value as a dimension. Depending on database configuration, a single set of reference dimension tables can be shared across ODS instances.
4. Maintain timely data
Reporting requirements and schedules determine how often you need to refresh data into the reporting system. Risk managers may require a single end-of-day run, multiple daily runs or near real-time reporting. Several methods are available depending on this schedule:
- Wipe and Load – Predetermined intervals, trade data is removed (or archived) and replaced into the staging tables. Translation is then performed to populate the ODS for an accurate ‘point-in-time’ view of exposures and P&L.
- Change Data (Periodic) – At defined intervals, new and updated trades are loaded into ODS staging tables. Subsequent population of warehouse fact tables can be scheduled or performed ad-hoc.
- Change Data (Real-time) – When any change occurs, trades are published into ODS staging tables. Similarly, any changes to reference data are used to update dimensions. Population of the warehouse fact tables can be scheduled or performed ad hoc, with the goal of the most recent data always being present.
5. Views are key
Timely and complete warehouse data capture is critical. However, it is rendered ineffective if queries are written against it incorrectly. To address this issue and ensure accurate reports, you should restrict end users to SQL views that provide consistent query results. By consolidating complex logic into a few well-written and tested SQL statements, you will also reduce the technical burden from individual queries.
SQL SELECT statements only need to specify basic arguments, such as date to supply a complex report. Downstream systems benefit from SQL views as well. By utilizing views, a ‘single source of truth’ is maintained across integrated systems. Subsequent changes to the data model can be isolated from integrated systems by maintaining view consistency, significantly reducing the risk of errors and the need for remediation.
CONCLUSION
Each company’s systems landscape and reporting requirements are unique – but certain core principles remain constant. A solid foundation of master data, paired with a well-planned data warehouse strategy, populated in a timely manner, will meet reporting needs across commodities and disciplines. By confining complex translation and query logic to purpose-built code, accurate reports can be consistently generated both now and in the future.



